Utilizing Artificial Intelligence to Prepare Structured Abstracts in Brain Tumor Clinical Practice Guidelines in Japan – A Case Study
- 1. Department of Neurosurgery, Nagasaki University Graduate School of Biomedical Sciences, Japan
- 2. Department of Neurosurgery and Neuro-Oncology, National Cancer Center Hospital, Japan
- 3. Ministry of Health, Labour and Welfare, the Labor Insurance Appeal Committee, Japan
- 4. Department of Neurosurgery, Oita University Faculty of Medicine, Japan
Abstract
Background: Developing clinical practice guidelines requires significant time and effort, especially in the systematic review process to create structured abstracts, and large language models (LLMs) have the potential to help this process. This study describes the use of artificial intelligence (AI) to create structured abstracts for the Brain Tumor Clinical Practice Guideline 2025 by the Japan Society for Neuro-Oncology.
Methods: Ten papers on palliative care and quality of life for diffuse glioma patients were selected in this study. First, the abstracts were retrieved from PubMed and translated into Japanese using ChatGPT 4o. Then, the structured abstracts were refined manually. Second, ChatGPT 4 Turbo processed the full text PDFs to optimize the content. Then, the similarity between the original and AI-generated abstracts was assessed using sentence-bidirectional encoder representations from transformers (S-BERT).
Results: The AI successfully generated structured abstracts within a few minutes. The subjective evaluation showed that the AI-generated translations were useful. The S-BERT analysis improved the similarity scores from the primary phase (0.581) to the secondary phase (0.662), with a p-value of 0.01. Note that no significant correlation was observed between the S-BERT scores and the document length.
Conclusion: AI-assisted structured abstract generation proved to be a practical and time-saving approach in guideline development. However, human reviews remain crucial to ensure sufficient quality. Future research should focus on blind evaluations and utilize larger datasets for further validation,
Keywords
• Clinical Practice Guidelines
• Generative Artificial Intelligence
• Large Language Models
• Structured Abstracts
Citation
Ujifuku K, Narita Y, Ueki K, Hata N, Matsuo T (2025) Utilizing Artificial Intelligence to Prepare Structured Abstracts in Brain Tumor Clinical Practice Guidelines in Japan – A Case Study. J Cancer Biol Res 12(1): 1152.
ABBREVIATIONS
AI: Artificial Intelligence; BERT: Bidirectional Encoder Representations from Transformers; BTCPG-AO: The Brain Tumor Clinical Practice Guideline for Astrocytoma and Oligodendroglioma; CQs: Clinical Questions; LLMs: Large Language Models; NLP: Natural Language Processing; PICO: Patient or Problem, Intervention, Comparison, Outcome; S-BERT: Sentence-Bidirectional Encoder Representations from Transformers.
INTRODUCTION
Clinical practice guidelines systematically present an overview of the best evidence-based tests and treatments, and developing such guidelines requires considerable human resources and time [1,2].
With the advancement of generative artificial intelligence (AI), large language models (LLMs) have become widely accessible. LLMs are natural language processing (NLP) models trained on extensive datasets that can perform various NLP tasks, e.g., text classification, sentiment analysis, information extraction, sentence summarization, text generation, and question answering [3,4].
One example of a general NLP model is bidirectional encoder representations from transformers (BERT) model [5]. There are several variations of BERT, including sentence-BERT (S-BERT) [6], and BioBERT [7], which have been studied for use in sentence similarity evaluation and AI-based medical data analysis tasks.
Previous studies have also demonstrated that LLMs can help develop clinical practice guidelines. For example, Oami et al., reported the usefulness of LLMs in selecting original articles for structured abstracts [8].
Readers of Journal of Cancer Biology and Research are exploring the evolving role of AI in medical documentation and guideline formulation. The authors investigated the use of LLMs in a literature review phase after literature selection during the development of the Brain Tumor Clinical Practice Guideline for Astrocytoma and Oligodendroglioma (BTCPG-AO) in the Japan Society for Neuro-Oncology, which took place from September 2024 to February 2025. The results are evaluated subjectively and reported alongside quantitative assessments made using S-BERT and BioBERT.
MATERIAL AND METHODS
In this study, the authors first obtained permission from the guideline working group for astrocytoma and oligodendroglioma for this project, and the research protocols were approved by the institutional review board of Nagasaki University (number 25012302). Consent was not required because this study involved no human subjects.
Materials
BTCPG-AO set clinical questions (CQs) and selected several papers for each CQ following the standard method for the systematic review, and several reviewers were asked to systemically review those papers and generate structured abstracts. The first author of this paper reviewed and prepared a structured abstract of 10 selected papers for a CQ (CQ8: regarding palliative care and quality of life) and generated a structured abstract of on four aspects, i.e., patient or problem, intervention, comparison, outcome (PICO). The literature data (PDF files) were provided by the guideline working group. The topics of this CQ primarily involved palliative care, end of-life care, and quality of life, which are topics that the authors (neurosurgeons) are not necessarily familiar with (Table 1 and Supplementary Table 1).
|
Reference number |
Titles |
Design |
Abstract words |
Full-text words (pages ) |
S-BERT 1 |
S-BERT 2 |
S-BERT 3 |
|
CQ8-2-12 (10) |
Dyadic versus individual delivery of a yoga program for family caregivers of glioma patients undergoing radiotherapy: Results of a 3-arm randomized controlled trial. |
3-arm randomized controlled trial. |
266 |
3958 (11) |
0.581 |
0.562 |
0.528 |
|
CQ8-2-13 (14) |
Monitoring of Neurocognitive Function in the Care of Patients with Brain Tumors. |
Review |
152 |
3667 (14) |
0.627 |
0.865 |
0.955 |
|
CQ8-2-14 (15) |
Evaluation of a multimodal rehabilitative palliative care programme for patients with high-grade glioma and their family caregivers. |
Longitudinal study |
225 |
4704 (15) |
0.564 |
0.560 |
0.508 |
|
CQ8-2-15 (16) |
Palliative care in glioma management. |
Review |
196 |
2578 (6) |
0.547 |
0.726 |
0.727 |
|
CQ8-2-16 (17) |
Mapping the nature of distress raised by patients with high-grade glioma and their family caregivers: a descriptive longitudinal study. |
Longitudinal study |
259 |
3033 (8) |
0.559 |
0.726 |
0.630 |
|
CQ8-2-17 (18) |
Symptoms of Depression and Anxiety in Adults with High- Grade Glioma: A Literature Review and Findings in a Group of Patients before Chemoradiotherapy and One Year Later. |
Review and longitudinal study |
220 |
4711 (14) |
0.508 |
0.619 |
0.473 |
|
CQ8-2-18 (19) |
Health-related quality of life in adults with low-grade gliomas: a systematic review. |
Systematic review |
259 |
5086 (27) |
0.446 |
0.539 |
0.417 |
|
CQ8-2-19 (20) |
Study of Association of Various Psychiatric Disorders in Brain Tumors. |
Prospective study |
249 |
3392 (10) |
0.580 |
0.528 |
0.536 |
|
CQ8-2-20 (21) |
Experiences of work for people living with a grade 2/3 oligodendroglioma: a qualitative analysis within the Ways Ahead study. |
Descriptive qualitative study |
253 |
4094 (10) |
0.579 |
0.703 |
0.728 |
|
CQ8-2-21 (22) |
Palliative care for patients with glioma: A recent scientometric analysis of the Web of Science in 2022. |
Scientometric analysis |
407 |
3369 (11) |
0.490 |
0.811 |
0.749 |
Table 1: The reference numbers correspond to the Brain Tumor Clinical Practice Guideline for Astrocytoma and Oligodendroglioma by the Japan Society for Neuro-Oncology. We counted the number of words in the sentences using Microsoft Word. BioBERT compared the original and AI-generated abstracts using prompts A (BioBERT 1), B (BioBERT 2), and C (BioBERT3), as shown in Table 2. Some research papers demonstrated clear similarities in BioBERT analyses; however, we also identified several outliers (CQ8-2-16 and 21). In addition, we observed changes that suggested possible overoptimization in the BioBERT analyses. BERT, bidirectional encoder representations from transformers
|
Reference number |
Titles |
Design |
BioBERT 1 |
BioBERT 2 |
BioBERT 3 |
|
CQ8-2-12 (10) |
Dyadic versus individual delivery of a yoga program for family caregivers of glioma patients undergoing radiotherapy: Results of a 3-arm randomized controlled trial. |
3-arm randomized controlled trial. |
0.966 |
0.972 |
0.975 |
|
CQ8-2-13 (14) |
Monitoring of Neurocognitive Function in the Care of Patients with Brain Tumors. |
Review |
0.944 |
0.972 |
0.980 |
|
CQ8-2-14 (15) |
Evaluation of a multimodal rehabilitative palliative care programme for patients with high-grade glioma and their family caregivers. |
Longitudinal study |
0.957 |
0.930 |
0.981 |
|
CQ8-2-15 (16) |
Palliative care in glioma management. |
Review |
0.974 |
0.971 |
0.986 |
|
CQ8-2-16 (17) |
Mapping the nature of distress raised by patients with high-grade glioma and their family caregivers: a descriptive longitudinal study. |
Longitudinal study |
0.298 |
0.119 |
0.147 |
|
CQ8-2-17 (18) |
Symptoms of Depression and Anxiety in Adults with High-Grade Glioma: A Literature Review and Findings in a Group of Patients before Chemoradiotherapy and One Year Later. |
Review and longitudinal study |
0.964 |
0.967 |
0.943 |
|
CQ8-2-18 (19) |
Health-related quality of life in adults with low-grade gliomas: a systematic review. |
Systematic review |
0.833 |
0.854 |
0.793 |
|
CQ8-2-19 (20) |
Study of Association of Various Psychiatric Disorders in Brain Tumors. |
Prospective study |
0.982 |
0.964 |
0.979 |
|
CQ8-2-20 (21) |
Experiences of work for people living with a grade 2/3 oligodendroglioma: a qualitative analysis within the Ways Ahead study. |
Descriptive qualitative study |
0.923 |
0.705 |
0.722 |
|
CQ8-2-21 (22) |
Palliative care for patients with glioma: A recent scientometric analysis of the Web of Science in 2022. |
Scientometric analysis |
0.235 |
0.953 |
0.959 |
Supplementary Table 1: The reference numbers correspond to the Brain Tumor Clinical Practice Guideline for Astrocytoma and Oligodendroglioma by the Japan Society for Neuro-Oncology. We counted the number of words in the sentences using Microsoft Word. BioBERT compared the original and AI-generated abstracts using prompts A (BioBERT 1), B (BioBERT 2), and C (BioBERT3), as shown in Table 2. Some research papers demonstrated clear similarities in BioBERT analyses; however, we also identified several outliers (CQ8-2-16 and 21). In addition, we observed changes that suggested possible overoptimization in the BioBERT analyses. BERT, bidirectional encoder representations from transformers.
Subjective evaluation
The usefulness of the Japanese translation of the structured abstracts is described by presenting an example to the readers of Journal of Cancer Biology and Research (Supplementary Table 2).
|
English (Translated from Japanese by ChatGPT) |
|
Patient: A total of 67 family caregivers of glioma patients were included (mean age: 53 years, 79% female, 78% non-Hispanic White). Caregivers provided care to patients and were potentially affected in terms of depression and quality of life. Intervention: Dyadic yoga (DY) and individual caregiver yoga (CY) interventions were evaluated as supportive care strategies. Both DY and CY interventions consisted of 15 sessions. Comparison: The DY and CY intervention groups were compared to the usual care (UC) group. Outcome: Caregivers’ depressive symptoms, quality of life (QOL), and responses to caregiving were assessed at baseline, 6 weeks, and 12 weeks. Results showed that caregivers in the CY group reported greater subjective benefits than those in the DY group, along with improvements in mental QOL and financial burden. These findings suggest that individual interventions may be effective for vulnerable caregiver populations. |
Supplementary Table 2: An example of structured abstract CQ8-2-12 for initial analysis. Readers whose native language is English may find it difficult to appreciate its usefulness; however, readers whose native language is Japanese appear to grasp the content of the abstract more easily.
Primary analysis (draft preparation phase)
To prepare a structured abstract within approximately one month and without research funding from the guideline working group, we created simple structured abstracts. Here we searched for the abstracts of the original articles in PubMed (https://pubmed.ncbi.nlm.nih. gov/) and obtained the corresponding text data. Then, the text data were translated into Japanese using ChatGPT 4o (OpenAI; from September to October 2024). Instructions for rewriting the abstracts into structured abstracts were provided to ChatGPT. Note that the default ChatGPT 4o did not fully understand the concept of structured abstracts; thus, we created specific prompts (Table 2A). Based on the simple structured abstracts, the first author reviewed the entire paper based on PICO and submitted the final version of the structured abstracts according to the specified format before the deadline.
|
Prompt |
English (Translated from Japanese by ChatGPT) |
Annotation |
|
A |
Put the text into a structured abstract, it is a summary of the Patient (characteristics of the group of patients in the study), Intervention (treatment to be tested), Comparison (standard treatment or control to be compared), and Outcome (endpoints to be evaluated)”. |
Used for the primary analysis. |
|
B |
Translate the full text of the article in PDF data into Japanese and summarize the translated text in a structured abstract. A structured abstract is a rewritten summary of the design, objectives, subjects, setting, intervention, primary endpoints, main results, and conclusions. Output the results as text data without line breaks. |
Used for the secondary analysis. The last line was added for input to the Python code (Supplementary Table 2). |
|
C |
Translate the main text of the paper from the PDF data and summarize the translation into a structured abstract. A structured abstract consists of the following sections: Design, Objective, Participants, Setting, Intervention, Primary Outcome Measures, Main Results, and Conclusion. In the Design section, include only the study design in a few words. Avoid repeating the same descriptions in the Objective, Intervention, Setting, and Primary Outcome Measures sections. In the Participants section, exclude exclusion criteria. Output the results as plain text data without line breaks. |
Used for the tertiary analysis. The results obtained using prompt B were reviewed, leading to the creation of a new aimed at optimizing the outcomes. However, issues with overadaptation emerged; thus, making the usefulness of the results was subtle. |
Table 2: Prompts for Generative AI.
Secondary analysis (method optimization phase)
After the initial deadline, further optimization was performed using ChatGPT 4 Turbo (OpenAI) in February 2025. Here, we uploaded literature PDF files to ChatGPT 4 Turbo and input prompts according to the specifications provided by the guideline working group, excluding the reviewer’s comments (Table 2B and 2C).
Verification of text similarity
To validate the similarity of the AI-generated Japanese text and the abstracts created by the first author, we employed S-BERT and BioBERT for quantification [6,7]. This analysis was performed using Google Colaboratory (https://colab.research.google.com/?hl=ja) and Python from January to February 2025 [9]. Note that the Python code was generated with the assistance of ChatGPT Turbo (Figure 1 and Supplementary Table 3).
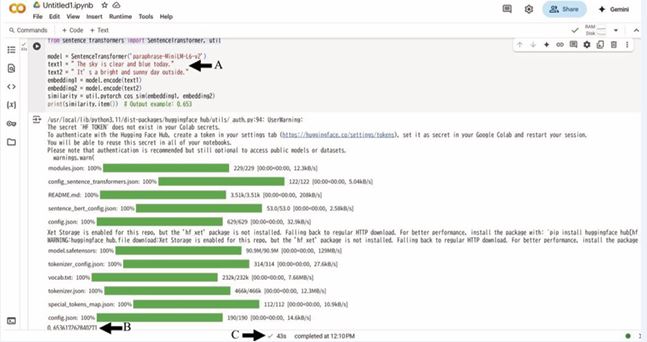
Figure 1: Execution of Python code.
This figure illustrates the execution of the Python code in Google Colaboratory. Arrow A indicates where the example sentences (“The sky is clear and blue today” and “It’s a bright and sunny day outside”) both entered as text data without line breaks. Arrow B presents the S-BERT value of 0.653. Arrow C shows that the total processing time was 43 s; however, most of this time was spent on package deployment. Once the package was deployed, the process was completed within a few seconds, even for the longer sentences analyzed in this study.
Supplementary Table 3: The Python code used in this study.
|
Methods |
Python code |
|
Sentence-BERT |
from sentence_transformers import SentenceTransformer, util model = SentenceTransformer('paraphrase-MiniLM-L6-v2') text1 = " The sky is clear and blue today." text2 = " It’s a bright and sunny day outside." embedding1 = model.encode(text1) embedding2 = model.encode(text2) similarity = util.pytorch_cos_sim(embedding1, embedding2) print(similarity.item()) # Output example: 0.653 |
|
BioBERT |
import torch from transformers import AutoTokenizer, AutoModel from sklearn.metrics.pairwise import cosine_similarity import numpy as np model_name = "dmis-lab/biobert-base-cased-v1.1" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModel.from_pretrained(model_name) def get_embedding(text): inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512) with torch.no_grad(): outputs = model(**inputs) cls_embedding = outputs.last_hidden_state[:, 0, :].numpy() return cls_embedding def calculate_similarity(text1, text2): emb1 = get_embedding(text1) emb2 = get_embedding(text2) similarity = cosine_similarity(emb1, emb2)[0][0] return similarity text1 = "Aspirin is commonly used for pain relief and fever reduction." text2 = "Aspirin is frequently prescribed to reduce pain and fever." similarity_score = calculate_similarity(text1, text2) print(f"Text Similarity Score: {similarity_score:.4f}") # Output example: 0.989 |
Statistical analysis
GraphPad PRISM 8.4.3 was employed to perform a one way ANOVA and correlation analysis. Here, a significance level of 5% was set to determine the statistically significant differences.
RESULTS
Subjective evaluation in the primary analysis
Within a few minutes, simple Japanese-structured abstracts were generated from the original paper’s abstract using AI. Notably, the CQ8-2-12 literature was relatively easy to understand, even though it included the term “dyadic yoga,” which was unfamiliar to the first author. In addition, a few relevant references were searched in PubMed (Supplementary Table 1) [10]. The usefulness of the Japanese translation of the original articles was evident for native speakers of Japanese. Initially, the practicality of this method to analyze review articles was uncertain due to the limited scope of articles and the need to reread the articles for clarity.
Quantitative evaluation
We quantitatively compared the similarity between the structured abstracts submitted by the first author and the two AI-generated structured abstracts. S-BERT excels at detecting similarities in sentence meanings [6], where a score of 1.0 indicates an exact match and a score closer to 0 suggests a greater disparity in meaning, as shown in Figure 1 (Arrow A). It was anticipated that sentences paraphrased with similar content would receive scores ranging from 0.6 – 0.8 or higher (Arrow B). We then employed BioBERT to generate embedding vectors and calculated the cosine similarity, as shown in Supplementary Table 1. Here, the interpretation of the results was consistent with the approach used for S-BERT. The corresponding results are shown in Table 1. The average S-BERT values for the primary, secondary, and tertiary analyses were 0.581, 0.662, and 0.625, respectively, indicating a statistically significant improvement (p = 0.01). No statistically significant correlation was observed between the S-BERT value and the number of words or pages in the original articles. Although the results of the BioBERT analysis were extremely high, no statistically significant differences were observed between the documents (p = 0.059).
DISCUSSION
This study has documented an example of improvement achieved through trial and error while beginning work in generative AI. However, there are still opportunities for refinement, e.g., limiting the word count in the abstract. In addition, a previous study suggested that the performance of generative AI could be enhanced by utilizing better prompts [8]. In this study, we attempted to replicate this investigation; however, we experienced mixed outcomes. Prompt C in Table 2 suggested that overadaptation improved performance in some studies, and other papers have reported a decline in performance (Table 1). Thus, further optimization of the prompts should be addressed in future work.
The machine-translated Japanese versions were highly beneficial in terms of understanding the original articles (Supplementary Table 2). Note that this study was conducted in Japanese; however, the method can be applied to other languages with well-developed machine translation from English.
Although no significant differences were identified in the current study, this method is valuable when conducting thorough examinations of articles with extensive text, e.g., review papers (Table 1). However, with a larger sample size, there may be potential to discover significant differences.
It is also possible that BERT is not widely recognized by medical professionals. This study attempted to quantify sentence similarity using S-BERT. The optimization of the prompts for generative AI has been validated quantitively. Due to BioBERT’s emphasis on the medical field, it was not suitable for this study, which attempted to identify the differences in sentence similarity (Table 1). However, in the future, BioBERT and others could play a significant role in the application of NLP in medical information utilization [7- 11].
We believe that this report effectively demonstrates that AI can be employed to create structured abstracts with a practical level of usability, which is expected to reduce labor and time costs in the development of future clinical practice guidelines.
However, several limitations of this study should be acknowledged. First, the analysis was performed using the free version of ChatGPT in conjunction with other tools. Although the latest version, i.e., ChatGPT 5, was accessible, its restrictions on the daily analysis volume extended the process. Thus, if the budget permits, acquiring a paid version of ChatGPT would be advantageous. Generative AI is evolving rapidly, and further cost reductions are expected [12]. Next, the S-BERT value may differ between the Japanese and English languages. For example, Japanese texts similar to the English examples shown in Figure 1 obtained a value of approximately 0.85 (data not shown). In addition, the analyses partially relied on the text of AI-generated abstract; thus, the potential for confounding factors cannot be excluded. The low S-BERT values reported in the original articles may be attributed to the reviewer’s rephrasing of several sections, which could partially explain why the secondary and tertiary analyses did not yield improved values. Therefore, in the future, conducting a blind study that includes reviewers may be warranted. In addition, the generated AI can make mistakes or overlook certain tasks. For example, we attempted to have ChatGPT count the number of words in this analysis; however, this did not work effectively, and the analysis load was high. Thus, the word count task was performed using Microsoft Word (Table 1). Ensuring accuracy and verifying the final content is a responsibility that lies with humans. Finally, Akira Watanabe, a renowned Japanese chess (Shogi) player, stated, “The current Shogi AI does not answer the question ‘Why ?’; it only provides evaluation values. You must think about ‘Why ?’ on your own (in Japanese, viewed on July 28, 2021)” [13]. Even though AI can be used to generate structured abstracts quickly, ultimately, humans must make value judgments about the reasons behind AI’s conclusions. In this study, the systemic reviewer’s comments were excluded from the analysis; however, this remains a crucial issue for systemic reviewers in the future.
CONCLUSION
Humans must continue to review and evaluate AI generated results based on their medical knowledge and experience; however, AI-assisted structured abstract generation in guideline development is a practical and time-saving approach.
ACKNOWLEDGMENTS
This research was partially supported in part by a Grant-in-Aid for Scientific Research from the Ministry of Education, Culture, Sports, Science and Technology of Japan (JSPS KAKENHI, #21K09154 for KU.)
The authors would like to pay tribute to the original research teams (10, 14-22) and the developers of the tools. In this study, we utilized resources such as PubMed (National Library of Medicine), ChatGPT (OpenAI), Google Gemini (Google), DeepL (DeepL GmbH), and Grammarly (Grammarly Inc.).
We would also like to thank Enago (www.enago.jp) for the English language review.
REFERENCES
- Grimshaw JM, Eccles MP, Lavis JN, Hill SJ, Squires JE. Knowledge translation of research findings. Implement Sci. 2012; 7: 50.
- Guyatt G, Oxman AD, Akl EA, Kunz R, Vist G, Brozek J, et al. GRADE guidelines: 1. Introduction-GRADE evidence profiles and summary of findings tables. J Clin Epidemiol. 2011; 64: 383-394.
- Tom Brown BM, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems (NeurIPS 2020). 2020; 33: 1877-1901.
- Ashish Vaswani NS, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, ?ukasz Kaiser, et.al. Attention is All you Need. Neural Information Processing Systems (NeurIPS). 2017; 30: 1-11.
- Devlin JMC, Lee K, Toutanova K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2019.
- Reimers N, Gurevych I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Empirical Methods in Natural Language Processing. 2019.
- Lee J, Yoon W, Kim S, Kim D, Kim S, So CH, et al. BioBERT: a pre- trained biomedical language representation model for biomedical text mining. Bioinformatics. 2020; 36: 1234-1240.
- Oami T, Okada Y, Nakada TA. Performance of a Large Language Model in Screening Citations. JAMA Netw Open. 2024; 7: e2420496.
- Guido van Rossum FLDJ. Python: A Programming Language for Software Integration and Development. 2001.
- Milbury K, Whisenant M, Weathers SP, Malliaha S, Snyder S, Jackson N, et al. Dyadic versus individual delivery of a yoga program for family caregivers of glioma patients undergoing radiotherapy: Results of a 3-arm randomized controlled trial. Cancer Med. 2023; 12: 7567-7579.
- Zheng Y, Gan W, Chen Z, Qi Z, Liang Q, Yu PS. Large Language Models for Medicine: A Survey. 2024.
- DeepSeek-AI, Liu A, Feng B, Xue B, Wang B, Wu B, et al. DeepSeek-V3 Technical Report. arXiv. 2024; 2412: 19437.
- Watanabe A. What are today’s top professionals researching? Akira Watanabe Meijin’s lecture on standard moves in shogi. YouTube. 2021
- Noll KR, Bradshaw ME, Parsons MW, Dawson EL, Rexer J, Wefel JS. Monitoring of Neurocognitive Function in the Care of Patients with Brain Tumors. Curr Treat Options Neurol. 2019; 21: 33.
- Nordentoft S, Dieperink KB, Johansson SD, Jarden M, Piil K. Evaluation of a multimodal rehabilitative palliative care programme for patients with high-grade glioma and their family caregivers. Scand J Caring Sci. 2022; 36: 815-829.
- Oberndorfer S, Hutterer M. Palliative care in glioma management. Curr Opin Oncol. 2019; 31: 548-553.
- Philip J, Collins A, Panozzo S, Staker J, Murphy M. Mapping the nature of distress raised by patients with high-grade glioma and their family caregivers: a descriptive longitudinal study. Neurooncol Pract. 2020; 7: 103-110.
- Ribeiro M, Benadjaoud MA, Moisy L, Jacob J, Feuvret L, Balcerac A, et al. Symptoms of Depression and Anxiety in Adults with High-Grade Glioma: A Literature Review and Findings in a Group of Patients before Chemoradiotherapy and One Year Later. Cancers (Basel). 2022; 14: 5192.
- Rimmer B, Bolnykh I, Dutton L, Lewis J, Burns R, Gallagher P, et al. Health-related quality of life in adults with low-grade gliomas: a systematic review. Qual Life Res. 2023; 32: 625-651.
- Sharma A, Das AK, Jain A, Purohit DK, Solanki RK, Gupta A. Study of Association of Various Psychiatric Disorders in Brain Tumors. Asian J Neurosurg. 2022; 17: 621-630.
- Walker H, Rimmer B, Dutton L, Finch T, Gallagher P, Lewis J, et al. Experiences of work for people living with a grade 2/3 oligodendroglioma: a qualitative analysis within the Ways Ahead study. BMJ Open. 2023; 13: e074151.
- Xiao Z, Chen W, Zhao H, Wang H, Zhao B, Liu D, et al. Palliative care for patients with glioma: A recent scientometric analysis of the Web of Science in 2022. Front Oncol. 2022; 12: 995639.