Measuring Formant Parameters via Pitch-Synchronous Analysis with Applications to Creative Voice Synthesis
- 1. Department of Applied Physics and Applied Mathematics, Columbia University, USA
Abstract
According to the transient theory of human voice production, the time between two adjacent glottal closing instants accurately defines the pitch period, and the sound waveform in each pitch period contains full information on the timbre of the voice. Therefore, using a pitch-synchronous analysis method, all formant parameters of the voice can be measured from the voice waveforms in each pitch period, including central frequency, intensity, and bandwidth of each formant. The results are independent of input parameters and reproducible. As examples, the formant parameters of five cardinal vowels measured from voice waveforms are presented. Using formant parameters measured from voice waveforms, creative voice synthesis is presented. As an application, creative singing synthesis from a score file and formant parameters is demonstrated.
Keywords
• Human voice
• Sound waveform
• Formants
• Voice synthesis
Citation
Chen CJ (2025) Measuring Formant Parameters via Pitch-Synchronous Analysis with Applications to Creative Voice Synthesis. Ann Otolaryngol Rhinol 12(2): 1358.
ABBREVIATIONS
EGG: Electroglottograph; PCM: Pulse-Code Modulation; LPC: Linear Predictive Coefficients; FFT: Fast Fourier Transform, GCI: Glottal Closing Instant, AI: Artificial Intelligence.
INTRODUCTION
Human voice production is an important physiological function within the medical discipline of otolaryngology and rhinology. Historically, there are two theories of human voice production, the transient theory and the source-filter theory [1-3]. The transient theory of human voice was first proposed by Leonhard Euler in 1727, completed in the modern form and published in 2016, called the timbron theory [1-3].The timbron theory of human voice production is a logical consequence of the observed temporal correlation between the voice signals and the simultaneously acquired electroglottograph (EGG) signals [4-6]. The working principle of EGG is shown in Figure 1.
Figure 1: A schematic of the electroglottograph. A high-frequency ac signal, typically 200 kHz, is applying on one side of the neck. An ac microammeter is placed on the other side of the neck. (a), when the glottis is open, the ac current is reduced. (b), when the glottis is closed, the ac current is increased.
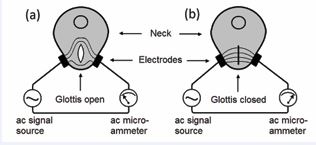
Two electrodes are pressed against the right side and the left side of the neck, near the vocal folds. A high-frequency electrical signal, typically 200 kHz, is applied to probe the electrical conductance between the two electrodes. (a). While the glottis is open, the conductance is lower, and the current is smaller. (b). While the glottis is closed, the conductance is greater, and the current is higher. Therefore, the glottal closing instant (GCI) can be determined to an accuracy of about 0.01 msec [4-6].
A ubiquitous experimental fact was observed in the temporal correlation between the voice signal and EGG signal [1-6], Figure 2.
Figure 2: Temporal correlation between the voice signal and the EGG signal. (a). Immediately after a glottis closing, there is a strong impulse of a negative perturbation pressure. (b). In the closed phase of glottis, the voice signal is strong and decaying. (c). The voice signal in the open phase of the glottis is much weaker. (d). Immediately before a glottal closing, there is a peak of positive perturbation pressure.
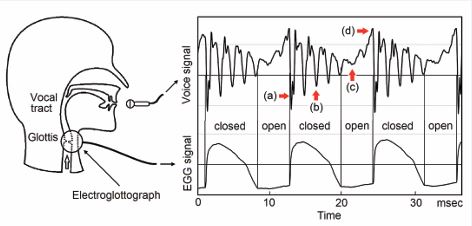
(a). Immediately after a GCI, a strong impulse of a negative perturbation pressure emerges. (b). During the closed phase of glottis, the voice signal is strong and decaying. (c). In the glottal open phase, the voice signal further decays and become weaker. (d). Immediately before a GCI, there is a peak of positive perturbation pressure. At a GCI, the slope of voice signal is continuous. The next GCI starts a new decaying acoustical wave, superposing on the tails of the previous decaying acoustical waves. The elementary decaying wave started at a GCI is determined by the geometry of the vocal tract, containing full information on the timber, thus called a timbron. The pitch period is defined as the time interval of two adjacent GCIs. The observed waveform in each pitch period contains the starting portion of the timbron in the current pith period and the tails of the timbrons of previous pitch periods, therefore contains full information on the timber of the voice.Formants are the most important parameters to characterize the timbre of human voice. In 2015, 22 voice scientists published a joint paper [7], entitled Toward a consensus on symbolic notation of harmonics, resonances, and formants in vocalization. According to the joint paper, formant is defined as a property of the sound of voice projected to the space. Each formant is characterized by three parameters, central frequency Fn , level or amplitude Ln , and bandwidth Bn [7].Traditionally, the formant parameters are extracted by the method of linear prediction coefficients (LPC) [8,9], based on the source-filter theory of human voice production [10]. For each formant, the LPC method can only provide the frequency and the bandwidth. The formant level is missing. Furthermore, the results of the formant frequencies using LPC method depend on an input parameter, the order p of the transfer function [8,9]. Therefore, that method is neither reproducible nor objective, and requires voice signals of many consecutive pitch periods with the same pitch frequency.Following the transient theory of human voice production, especially the modern version of timbron theory [1-3], a pitch-synchronous method to measure formants is developed [11]. From the waveform in each pitch period, formants with all parameters including central frequency, level, and bandwidth are obtained with a high reproducibility [11]. It offers a virtually unlimited opportunity for human voice research and applications, such as acoustic phonetics and creative voice synthesis.
MATERIALS AND METHOD
The source of data can be any high-quality recordings of voice, including speech and singing (without accompaniment). The voice signal is digitized and represented as PCM (pulse-code modulation) data. Many existing voice recordings also have simultaneously acquired EGG signals. Nevertheless, for voice recording without the simultaneous EGG signals, GCI can be extracted from the voice signal [3]. Since the invention of the pitch-synchronous overlap and add (PSOLA) for speech synthesis in the 1980s, in the speech technology community, a huge amount of high-quality simultaneous voice and EGG signals has been recorded. An example is the ARCTIC database, recorded and published by Carnegie Melon University [12]. Supported by the government, the data is publicly available. Spoken by three speakers, two male and one female, each reads a prepared text of 1132 sentences. Among the three speakers, the female speaker slt is often the prime choice. As an example, the sentence a0003 is For the twentieth time that evening the two men shook hands. The waveform and the corresponding segmentation points of part of the vowel [i] from the word “evening” is shown in Figure 3.
Figure 3: Part of the voice waveform of the vowel [i] in sentence a0003 of the ARCTIC database by speaker slt. The pitch-period segmentation points, generated from EGG signals, are shown as vertical lines. The Fourier transform of the voice waveform in the pitch period (a), is shown in Figure 4.
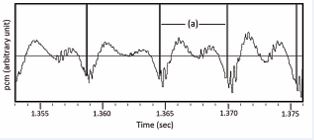
The amplitude spectrum is shown as the blue curve in Figure 4.
Figure 4: The amplitude spectrum of pitch period (a) in Figure 3, generated by the Python FFT program, is shown as the blue curve. Four formants are extracted from it. The spectrum regenerated from the formants is shown as the red curve.
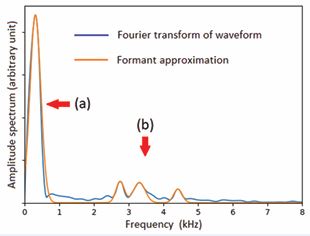
As shown, there are four prominent peaks in the spectrum. From each peak, there are three parameters: the frequency, the amplitude, and the curvature. They provide information of the three parameters for each formant: central frequency Fn , amplitude Cn , and bandwidth Bn .The algorithm of finding those formant parameters are described in Ref [11]. The parameters of the formats are shown in Table 1.. As shown, there is a strong formant of a low frequency, 315 Hz, shown as (a), and three weaker formants at higher frequencies between 2.5 kHz and 5 kHz, shown as (b). The ARCTIC database was collected in the 1990s. The sample rate was 32 kHz, and the signal quality was not great [12]. The formant parameters for five cardinal vowels and an unvoiced consonant [m] in this article were extracted from a modern recording with sample rate of 44.1 kHz [13]. See Tables 2-7. For example, the bandwidths of the formants in Table 4 are smaller than those in Table 1, indicating a better clarity.
Table 1: Formant parameters of vowel [i] from speaker slt
|
Number |
Frequency (Hz) |
Amplitude (au) |
Bandwidth (Hz) |
|
1 |
315 |
25328 |
224 |
|
2 |
2786 |
2882 |
171 |
|
3 |
3345 |
2717 |
241 |
|
4 |
4469 |
1840 |
174 |
Table 2: Formant parameters of vowel [a]
|
Number |
Frequency (Hz) |
Amplitude (au) |
Bandwidth (Hz) |
|
1 |
860 |
12592 |
57 |
|
2 |
1160 |
9490 |
46 |
|
3 |
1360 |
6969 |
48 |
|
4 |
2930 |
3715 |
68 |
Table 3: Formant parameters of vowel [e]
|
Number |
Frequency (Hz) |
Amplitude (au) |
Bandwidth (Hz) |
|
1 |
500 |
18522 |
39 |
|
2 |
2210 |
4432 |
95 |
|
3 |
2470 |
6567 |
73 |
|
4 |
3070 |
3244 |
145 |
Table 4: Formant parameters of vowel [i]
|
Number |
Frequency (Hz) |
Amplitude (au) |
Bandwidth (Hz) |
|
1 |
240 |
20348 |
60 |
|
2 |
2240 |
1958 |
104 |
|
3 |
3040 |
2262 |
125 |
|
4 |
3250 |
3198 |
148 |
Table 5: Formant parameters of voiced consonant [m]
|
Number |
Frequency (Hz) |
Amplitude (au) |
Bandwidth (Hz) |
|
1 |
200 |
29852 |
50 |
|
2 |
860 |
844 |
49 |
|
3 |
1350 |
1713 |
69 |
|
4 |
2140 |
1257 |
96 |
Table 6: Formant parameters of vowel [o]
|
Number |
Frequency (Hz) |
Amplitude (au) |
Bandwidth (Hz) |
|
1 |
220 |
2103 |
57 |
|
2 |
460 |
7725 |
36 |
|
3 |
730 |
5635 |
43 |
|
4 |
2850 |
921 |
85 |
Table 7: Formant parameters of vowel [u]
|
Number |
Frequency (Hz) |
Amplitude (au) |
Bandwidth (Hz) |
|
1 |
170 |
27813 |
44 |
|
2 |
480 |
4954 |
52 |
|
3 |
1500 |
0 |
50 |
|
4 |
2500 |
0 |
50 |
In the middle of the 20th century, formant-based voice synthesis was developed and applied [14]. Nevertheless, the quality of the results was poor, because the formant parameters were not properly obtained, and the theory of voice production was inaccurate. Then, concatenative or unit-selection synthesis method emerged [14]. It creates new audio by combining short fragments of pre-recorded voice, The artificial intelligence (AI) further improves the quality [15]. It can create highly human-like voice to mimic a single speaker or a single singer. However, currently, the raw waveform is taken as the target data. It requires a huge amount of prerecorded and labeled voice waveforms from a single person. Discontinuities at segment boundaries occur frequently. New style of voice cannot be created. The timbron theory and the pitch-synchronous analysis method to measure formant parameters can significantly improve the quality of creative voice synthesis. It opens the door to create new voices with full control of details.Here we present how to generate timbrons from formants and how to assemble them to create voice.As shown in Figure 2(d), a timbron is not started at a GCI. Immediately before A GCI, there is a peak of positive perturbation pressure. For definitiveness, we assume that the sample rate is 44.1 kHz. Assuming the length of a timbron is 1000 PCM points, which is about 22.6 msec, a GCI can be set at the 100th point of PCM, which is about t0 =2.26 msec. The expression of a timbron x(t) is
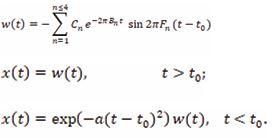
Figure 5: The timbron of vowel [a].
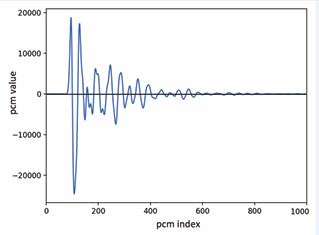
Here w(t) is the waveform of the formants, and the constant a is chosen to make the waveform looks reasonable. From the formants measured from voice waveforms, the timbrons of six basic phones are shown in Figures 5 through 10.To generate a voice of a melody with a vowel in the form of an array of PCM as a function of time p(t), one starts with a desired melody, represented by a varying pitch period (the inverse of pitch frequency) as a function of time T(t) . The algorithm runs as follows. First, for the entire expected duration of the melody, set p(t) = 0. Take the desired point t1 as the starting point of the timbron of the first vowel. Add the entire timbron at and after the starting point t1 . Move the starting point by the pitch period, to find the starting point of the second timbron,
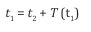
Then, superpose the second timbron starting at t2 . In general, T (t1 ) is smaller than the entire length of the timbron, 1000 PCM points or 22.6 msec. Therefore, the second timbron is always superposed on the tail of the first timbron. In general, we have
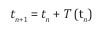
Repeat the procedure until the end of expected total time is reached. A complete PCM file of the output voice is generated. The entire algorithm is implemented in Python language, attached to the Article.
RESULTS AND DISCUSSION
Singing synthesis based on formants is not new [16 18]. Starting in the late 20th century, it was pioneered by a group led by John Sundberg in Stockholm [16,17], and a group led by Gerald and Xavier Rodet in Paris [18]. However, those studies were based on the source filter theory. The definition and method of measuring the formant parameters are not accurate. The formant parameters were manually defined by intuition [18]. The beginning of a timbron was formed by multiplying it with a cosine function [18]. The formants of different voices (S, A, T, and B) are separately defined [18]. According to the timbron theory of voice production, before a GCI, there is a peak of positive perturbative pressure to make the entire timbron continuous to the first derivative, and the formant frequencies for different voices are inversely proportional to the relative head sizes of the speaker which can be generated by multiplying with a numerical factor [3].
By applying the algorithm presented in the previous section, singing voice can be created. Let us start with singing of a single vowel. Two cases are studied in detail.Singing with a melody following a given score and a glissando passage. The source code for the two cases written in Python and formant data are attached for readers to review and test. The readers can freely improve the program and dataset.
The commend to create a melody is
Python3 melody.py score vowel key voice tempo
The argument score is the name of the score file; vowel is the name of the formant file, for example E is vowel [e]; key is a number in MIDI, for example, middle C is 60; voice can be one of C (child), S (soprano), A (alto) T (tenor), B (bass), and G (giant or contrabass); tempo is in beats per minute. For example,
creates a wav file for the first phrase of Eduard Grieg’s Morning Mode in Peer Gynt by a tenor singer in vowel A of G major with tempo of 60 beats per minute. To synthesize a glissando passage, use
Python3 glissando.py startnote endnote duration voice vowel vibratoamp
For example, by using
Python3 glissando.py 60 72 5 A O 50
A glissando passage from C4 to C5 in 5 seconds by an alto singer of vowel O with a vibrato amplitude of 50 cents (0.5 halftone) is generated in wav format. By setting vibratoamp to zero, a pure glissando passage is generated. (Supplementary File).
Using the above examples, many phenomena in singing can be studied. For example, the constructive superposition and destructive superposition, which can dramatically change the waveform and intensity of the output voice, can be systematically studied. It is a mechanism of formant tuning. On the other hand, the formant parameter files can be manually edited to create new versions of vowels and new vowels.Furthermore, the current algorithm of formant based singing synthesis enables very detailed control of the output sound wave. For example, for each note, an intensity profile can be implemented. For vibrato, all parameters including frequency, amplitude, and phase variations can be redefined. Because for every phone, there are four formants, a transition between two vowels can be implemented as a linear interpolation of the two sets of formant parameters. Diphthongs and triphthongs can be generated in that way. Using some extra effort, completeclassical vocal music pieces can be synthesized. Here we present two examples: Puccini’s humming chorus in Madam Butterfly, and Mozart’s Alleluia in Exultate and Jubilate. Those two pieces consist of vowels and consonants with a high sonority, which can be generated using the basic formant parameters. The results are presented in a video form. Although the performance in those video recordings is by far imperfect, it is the starting point to improve.To synthesize more complete vocal music pieces, consonants with less sonority, such as fricatives and stops, are required. According to Ladefoged and Maddieson [19], stops are the most important consonants, which are the only kind of consonants that occur in all languages. There is no explanation of stops in the source-filter theory. The transient theory is needed. For each language, the stops are different. Therefore, to create formant based representations of all consonants even for a single language, a significant amount of research work is required based on the basic framework presented here.The formant-based synthesizer based on the timbron theory of human voice production can also be the voice output module of a speech synthesizer assisted by AI [15]. By using AI to generate a human-readable prosody file, which bears some similarity to a score file for singing synthesis, then using that prosody file as an input to a formant-based voice synthesizer as presented here, a new type of speech synthesizers can be established, which has the advantages of both the classical formant synthesizers and the classical statistics-based synthesizers. It does not require a huge memory to store the waveform database. There are no discontinuities at segment boundaries. It allows manual control of fine details. Different voices and different speaking speeds can be created using the same prosody file without excessive memory.
CONCLUSION
Based on the timbron theory, which is a modern form of the transient theory of human voice production, a method of measuring formant parameters based on a pitch-synchronous analysis method is presented. From the voice waveform in each individual pitch periods of an adequately acquired digital records of human voice, a complete set of formant parameters, including central frequency, amplitude, and bandwidth, can be measured with reproducibility. Using the formant parameters measured from this method, creative voice synthesis can be performed. As an example, creative singing synthesis is demonstrated. A simple case of a single vowel according to a melody and glissando is presented. The source code and databases are open. Then, an experimental exploration of synthesizing two complete classical pieces is presented.
ACKNOWLEDGEMENTS
The algorithm of measuring formant parameters from voice recordings using the pitch-synchronous method presented in this paper was first tested on a large-scale and well-behaved set of recordings of individual vowels [11]. The author sincerely thanks Matheis Aaen, Ivan Mihaljevic, Howard Johnson and Ian Howell for providing high-quality voice recordings and inspiring discussions.
REFERENCES
- Svec JG, Schutte HK, Chen CJ, Titze IR. Integrative Insights to Myoelestic-Aerodynamic Theory of Acoustic Phonation, Scientific Tribute to Donald G. Miller. J Voice. 2023; 37: 305-323.
- Chen CJ, Miller DG. Pitch-Synchronous Analysis of Human Voice. J Voice. 2019; 34: 494-502.
- Chen CJ. Elements of Human Voice, World Scientific Publishing Co,New Jersey. 2017.
- Baken RJ. Electroglottography. J Voice. 1992; 6: 98-110.
- Herbst CT. Electroglottography - An Update. J Voice. 2020; 34: 503-526.
- Miller DG. Resonance in Singing. Inside View Press. 2008.
- Titze IR, Baken RJ, Bozeman KW, Granqvist, Henrich SN, Herbst CT, et al. Toward a consensus on symbolic notation of harmonics, resonances, and formants in vocalization. J Acoust Soc Am. 2015; 137: 3005-3007.
- Robiner LR, Schafer RW. Digital Processing of Speech Signals. Prentice-Hall. 1978.
- Markel JD, Gray AH. Linear Prediction of Speech. Springer Verlag, New York. 1976.
- Fant G. Acoustic Theory of Speech Production, De Gruyter Mouton. 1971.
- Aaen M, Mihaljevic I Johnson AM, Howell I, Chen CJ. A Pitch- Synchronous Study of Formants. J Voice. 2025.
- Kominek J, Black A. CMU ARCTIC Databases for Speech Synthesis. CMU Language Technologies Institute, Tech Report, CMU-LT1-03-177. 2003.
- King-TTS-012 Databases for Speech Synthesis, Speechocean, Beijing Haidian Ruisheng Science Technology Ltd, Beijing, China. Since 2021 it was renamed Dataocean AI Ltd.
- van Santen JPH, Sproat R, Olive J, Hirshberg J. Progress in Speech Synthesis. Springer. 2013.
- Tan X. Natural Text-to-Speech Synthesis. Springer. 2023.
- Sundberg J. Synthesis of Singing Voice, in Current Directions in Computer Music Research, edited by Mathews and Pierce. 1991; 45- 55.
- Sundberg J. Synthesizing singing, Proceeding of SMC’07, the FourthSound and Music Computing Conference. 2007.
- Bennett G, Rodat X. Synthesis of Singing Voice, in Current Directions in Computer Music Research, edited by Mathews and Pierce. 1991; 19-44.
- Ladefoged P, Maddieson I. The Sounds of the World’s Languages,Blackwell Publishers. 1996.








































































































































